Here is a thing about DNSSEC that people do not always talk about. When it works, you never notice it. But when it breaks — when a registry makes a mistake, when a signing key gets misconfigured, when someone updates a script and forgets a single dot at the end of a line — the internet just stops. Not slowly. Not with a nice error message. Just: stopped.
The technical term for what users see is SERVFAIL. The human translation is: this website does not exist right now, even though everything on the server side is perfectly fine. The domain is registered, the hosting is up, the application is running — but because DNS cannot verify the cryptographic signature on the answer, it refuses to give one.
This post is about the real incidents. The stories behind the SERVFAIL messages. What actually went wrong, how long it lasted, and what we should learn from it.
“DNSSEC is like a wax seal on an envelope. When the seal is intact, you know the letter was not tampered with. When the seal is broken — or someone forgot to put it on correctly — the whole envelope gets rejected, even if the letter inside is genuine.”
First — what does a broken chain of trust actually look like?
Before we go into the incidents, I want to show you something visual. DNSSEC works through a chain of trust that starts at the internet root zone and works its way down to individual domains. Every link in that chain has to verify the link below it.
When any one link breaks, everything below it becomes unreachable. Not degraded. Not slow. Unreachable. Here is what that looks like:

A healthy DNSSEC chain (left) passes trust all the way down. One broken link at the TLD level (right) makes every domain below it return SERVFAIL — even if those domains themselves are configured perfectly.
The important thing to understand: in every incident I am about to describe, the websites were fine. The servers were running. The application code had no bugs. The problem was always upstream, in the DNS trust layer, and the website owners had zero ability to fix it themselves.
🇸🇪 Incident 1: Sweden .se — A Single Missing Dot October 12, 2009
This one is almost a parable. Sweden’s .se domain was, at the time, the first top-level domain in the world to fully deploy DNSSEC. They were the pioneers. They had been doing this since 2005. And then one night, during routine maintenance, a script that updated the .se zone file ran without adding a single trailing dot to the DNS records.
A trailing dot. In DNS, the difference between se and se. is the difference between “a subdomain of the current zone” and “the top-level domain itself.” One character. Gone.
At around 21:19 local time, DNS lookups for every single .se domain started failing. All 900,000 of them. Aftonbladet. SVT. Swedish government websites. Email to Swedish domains stopped working. For people inside Sweden it was, as one journalist described it at the time, as if the Swedish internet had simply been switched off.
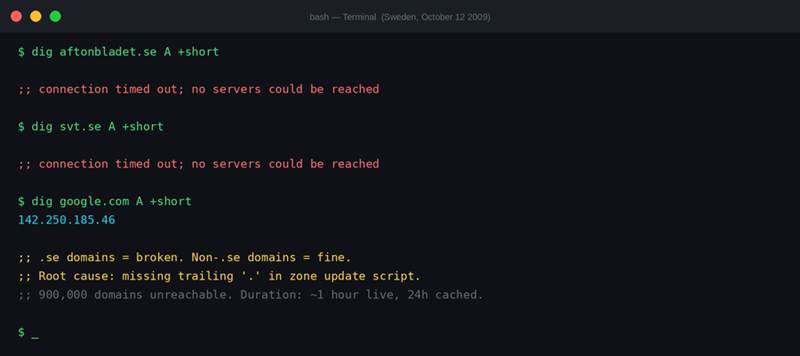
Screenshot 1: What a Swedish engineer would have seen that night. Any .se domain — timeout. Non-.se domains — perfectly fine. The problem was clearly scoped to the .se zone.
The fix took about an hour to push. But here is the part that made it worse: DNS is cached. The .se zone had a 24-hour TTL (Time to Live). That means ISPs around the world were holding a cached copy of the broken zone data, and they would keep serving it for up to 24 hours unless someone manually cleared the cache.
The major Swedish ISPs flushed their caches by around 23:30 that night. But ISPs outside Sweden? Many of them had no idea what happened, and their caches kept the broken records alive for the full TTL. For some users, .se was effectively broken for an entire day.
“The fix took one hour. The cleanup took a full day. Because of TTL caching, you cannot just push a fix and assume everyone gets it immediately.”
.se was not doing anything wrong. They were the most DNSSEC-experienced TLD in the world. The mistake was in a routine maintenance script that had a configuration error. A single missing character, propagated across 900,000 domains, cached worldwide for 24 hours.
🇸🇪 Incident 2: Sweden .se Again — Broken Signatures in the Zone File February 4, 2022
You would think that after what happened in 2009, .se would never have a DNSSEC incident again. Thirteen years later, they did.
This time it was more specifically a DNSSEC problem, not just a general DNS misconfiguration. Their signing system — the software responsible for generating and publishing DNSSEC signatures — produced incorrect signatures for some records in the .se zone file.
The first affected zone file was published at around 10:20 in the morning local time. The signing error meant that DNSSEC-validating resolvers around the world tried to verify the signatures, found them wrong, and returned SERVFAIL. From the outside, those domains simply did not exist.
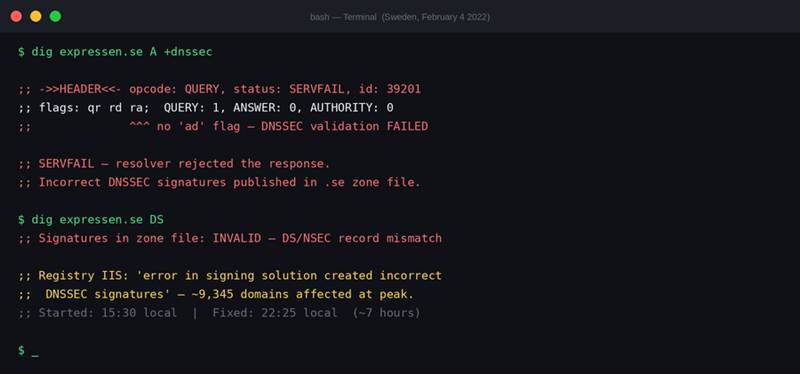
Screenshot 2: What happened when you queried a .se domain during the 2022 outage. SERVFAIL, no answer section, no AD flag. The resolver found the signature invalid and refused to return the IP address.
What makes this incident interesting technically is how it grew over time. Because .se publishes a new zone file every hour, each new file carried the signing error forward. The number of affected domains grew with each new file:
10:20 — 1,220 domains affected → by 15:00 — 9,345 domains affected
IIS (the Swedish Internet Foundation, who runs .se) caught the problem and published a corrected zone file at around 22:25 local time, seven hours after the first bad file appeared. Total domains with bad signatures at peak: roughly 9,345 out of 1.49 million.
The registry’s post-incident report said: “an error occurred in our signing solution and created incorrect DNSSEC signatures.” Not a hacker. Not a deliberate attack. A bug in the signing software, caught late, affecting thousands of Swedish websites for most of a working day.
🇳🇿 Incident 3: New Zealand .nz — A Key Rollover That Happened Too Soon May 29, 2023
DNSSEC requires you to rotate your signing keys periodically. This is good practice — using the same key for years increases the risk of someone eventually compromising it. The process of switching from an old key to a new one is called a key rollover, and it has to be done carefully.
InternetNZ, the registry for New Zealand’s .nz domain, learned this the hard way in 2023. During their annual Key Signing Key (KSK) rollover, they removed the old key from the zone before all resolvers around the world had finished caching the new one.
Here is why that matters. When a resolver caches a DNSSEC record, it also caches the key used to verify it. If you remove the old key from the live zone but the resolver is still using a cached record that points to that old key, the resolver tries to verify the signature against a key that no longer exists. Verification fails. SERVFAIL.
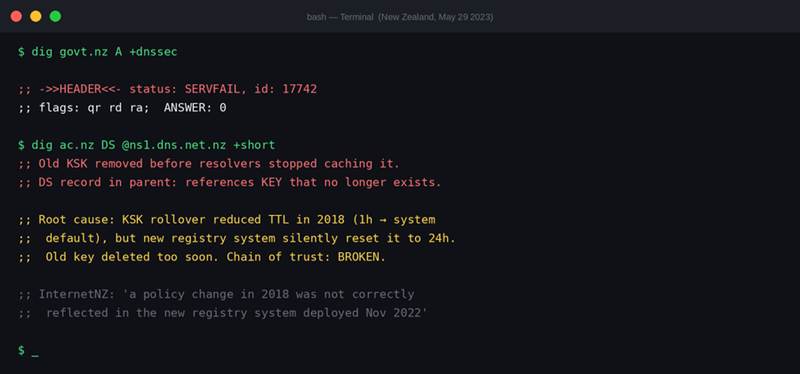
Screenshot 3: The .nz KSK rollover failure in action. The DS record in the parent zone pointed to a key that had already been removed. Resolvers with cached records referencing the old key returned SERVFAIL.
The root cause was subtle and worth understanding. In 2018, InternetNZ had reduced the TTL on their DS records from 24 hours down to 1 hour, to make future rollovers faster and safer. But in November 2022, they migrated to a new registry system (the IRS). That new system did not explicitly set TTLs on DS records — it just used the zone default, which was 24 hours.
Nobody noticed the TTL had silently reverted. So in May 2023, when they ran the KSK rollover using the old timing (designed for 1-hour TTLs), they removed the old key far too soon for a zone with 24-hour TTLs. Resolvers with cached DS records referencing the old key kept trying to use it for up to 24 hours.
InternetNZ published a detailed and admirably honest incident report. They noted that “a policy change in 2018 was not correctly reflected in the new registry system.” A configuration migration, done quietly, that had a delayed and invisible consequence that only surfaced fifteen months later during an otherwise routine key rotation.
“The mistake was made in November 2022. The outage happened in May 2023. Six months between cause and consequence, because the TTL misconfiguration was invisible until a key rollover exposed it.”
🇩🇪 Incident 4: Germany .de — The Biggest One Yet May 5, 2026
This one happened just a few weeks ago, and it is the largest DNSSEC failure in history to date. Germany’s .de top-level domain has 17.9 million registered domains — it is the second largest country-code TLD in the world. And on the evening of May 5, 2026, a significant portion of those domains went dark.
DENIC, the organization that runs .de, was performing a routine DNSSEC Key Signing Key rollover. They had just deployed the third generation of their internal signing system in April 2026. The system had been tested. It had been externally audited. And it had a bug that the tests did not catch.
At approximately 21:57 Central European Summer Time, DENIC’s nameservers started publishing DNSSEC signatures that could not be validated. Every DNSSEC-validating resolver in the world — Cloudflare’s 1.1.1.1, Google’s 8.8.8.8, countless ISP resolvers — was required by the DNSSEC specification to reject those signatures and return SERVFAIL.
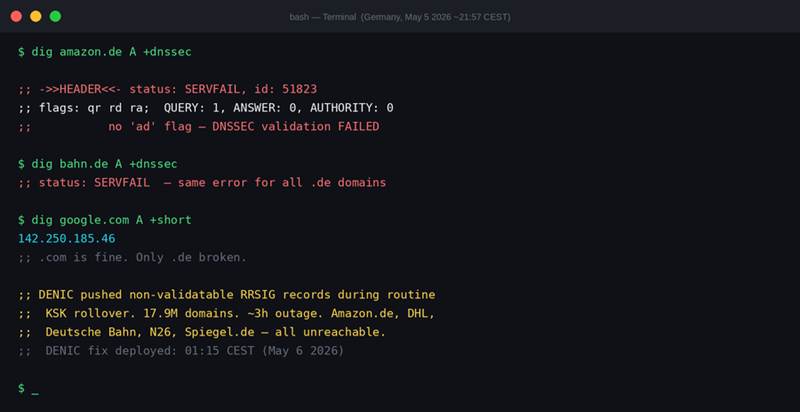
Screenshot 4: The .de outage from a terminal. Amazon.de, bahn.de — both SERVFAIL. Google.com works fine. The failure was precisely scoped to .de domains that used validating resolvers.
The list of affected sites reads like a directory of German daily life. Amazon.de. DHL. Deutsche Bahn’s ticket booking system. The N26 banking app. eBay.de. Spiegel.de. Hetzner hosting. Sparkasse. Web.de. Government portals. All of them — server running, CDN healthy, application code untouched — unreachable.
Downdetector’s German site logged roughly 10,000 alerts per minute at peak. Users in Germany, Switzerland, Austria, and beyond spent several hours unable to reach websites that were, technically speaking, perfectly operational.
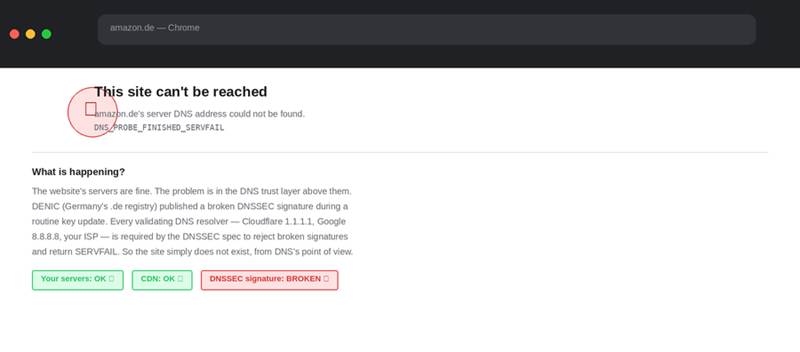
Screenshot 5: What a German user saw when trying to reach amazon.de during the outage. DNS_PROBE_FINISHED_SERVFAIL. The website was running. The problem was in the DNSSEC signature one level above it.
Cloudflare, who operate 1.1.1.1, made an emergency decision. They temporarily disabled DNSSEC validation for all .de domains — treating them as if they were unsigned — to restore connectivity to users while DENIC worked on the fix. This is called a Negative Trust Anchor (NTA), and it is exactly the kind of last-resort tool the RFC authors designed for this situation.
DENIC deployed a corrected zone at 00:08 local time on May 6, and full restoration was confirmed by 01:15. The total outage window was approximately three hours for users with no cached data, longer for others as the failure gradually caught up with expiring TTLs.
From DENIC’s own post-incident analysis: “a faulty piece of code was incorporated into the in-house development that was not fully covered by the test scenarios and went undetected during test runs and parallel operation prior to going live.”
As a precautionary measure, DENIC suspended all future key rollovers until the root cause is fully understood. DENIC is one of the most professionally managed TLD registries in the world. Their signing system had been externally audited. The bug still slipped through.
Putting it all together
Four incidents across four countries and seventeen years. Let me put them side by side:
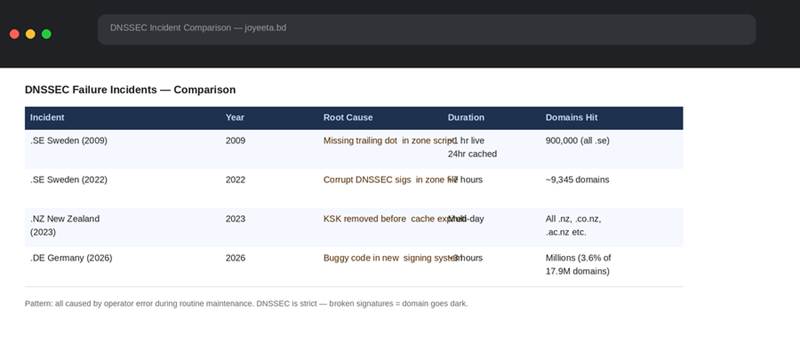
All four incidents compared by year, root cause, duration, and scale. Every single one happened during routine maintenance, not an attack.
The pattern jumps out immediately. Not one of these was a cyberattack. Not one was caused by someone trying to break something. Every incident happened during scheduled, planned, routine work. A script update. A zone file publication. A key rollover. An infrastructure migration.
And in every case, the domains themselves were perfectly fine. The hosting was up. The application was running. The problem was in the trust layer, one level above, in infrastructure that the website owners do not control and cannot fix.
“Your uptime monitor shows green across every server. Your support team is checking the wrong floor. The actual failure is upstream, invisible, and not yours to repair.”
The hard truth — and why DNSSEC is still worth it
I want to be honest with you, because I think the internet community sometimes oversimplifies this. DNSSEC has a real cost. These incidents caused real disruption to real people trying to do real things — book train tickets, check their bank balance, read the news. That is not nothing.
The critics of DNSSEC have a point when they say: a technology that can take down millions of websites because of a missing dot in a script is a technology that requires extraordinary operational discipline. DNSSEC adoption remains below 10% for most TLDs precisely because many operators look at these incidents and decide the risk is not worth it.
But here is the other side. The DNS attacks that DNSSEC prevents are not hypothetical. Cache poisoning attacks, BGP hijacking combined with DNS manipulation, state-level interception of DNS responses — these are real threats that have caused real harm to real users. DNSSEC, when working correctly, makes those attacks significantly harder.
The honest answer is: DNSSEC is a powerful security tool that requires careful operational practice. The failures we have seen are failures of process and tooling, not of the underlying concept. And the industry is learning — slowly, painfully, through incidents like these — how to run DNSSEC more reliably.
“DNSSEC failing loudly is still better than DNS lying quietly. A SERVFAIL tells you something is wrong. A cache poisoning attack sends you to the wrong place while showing you no error at all.”
What you can do — three lessions
1. If you run a domain, monitor DNSSEC separately. Your server uptime monitor will show green even during a DNSSEC failure. Use tools like DNSViz or Zabbix DNS checks to monitor the actual DNSSEC chain, not just whether your server responds to pings.
2. If you manage a TLD or run your own DNSSEC signing, treat key rollovers as high-risk events. The .nz and .de incidents both happened during rollovers. Test in a staging environment. Verify TTLs before and after migrations. Do not assume your new system inherited all the configuration of the old one.
3. If you hit SERVFAIL, check DNSSEC first. Many engineers waste hours checking servers, CDN, load balancers — when the problem is a broken DNSSEC signature one level above. Run dig yourdomain.com +dnssec and look at the status field. SERVFAIL with no AD flag is your clue.
The internet is a remarkably fragile and remarkably resilient thing at the same time. A missing dot can take down 900,000 websites. A bug in a signing system can darken the German internet for three hours. And yet, within hours, engineers fix it, caches clear, and everything comes back.
I think that is worth understanding, not just as a technical curiosity, but as a reminder of what DNS actually is: a globally distributed system of trust, operated by humans, that is impressive when it works and illuminating when it does not.